支持2种形式的Qwen3-TTS
支持的语言 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文和意大利文
Qwen-TTS是一项先进的语音合成技术,它可以将文字转换成听起来非常真实、自然的人声。它的一大亮点是能够根据文本内容自动调整语音的节奏和情感。
- 一是软件内置的本地Qwen3-TTS。
- 二是阿里百炼的在线API
Qwen3-TTS 本地内置 (离线版)
请确认已升级到 3.97+ 版本,内置可直接使用,固定使用 1.7B 尺寸的模型
第一次使用将自动下载base和custom 两套模型,合计大约8G,耐心等待,当然你也可以手动下载,手动下载方法如下
打开软件目录下的
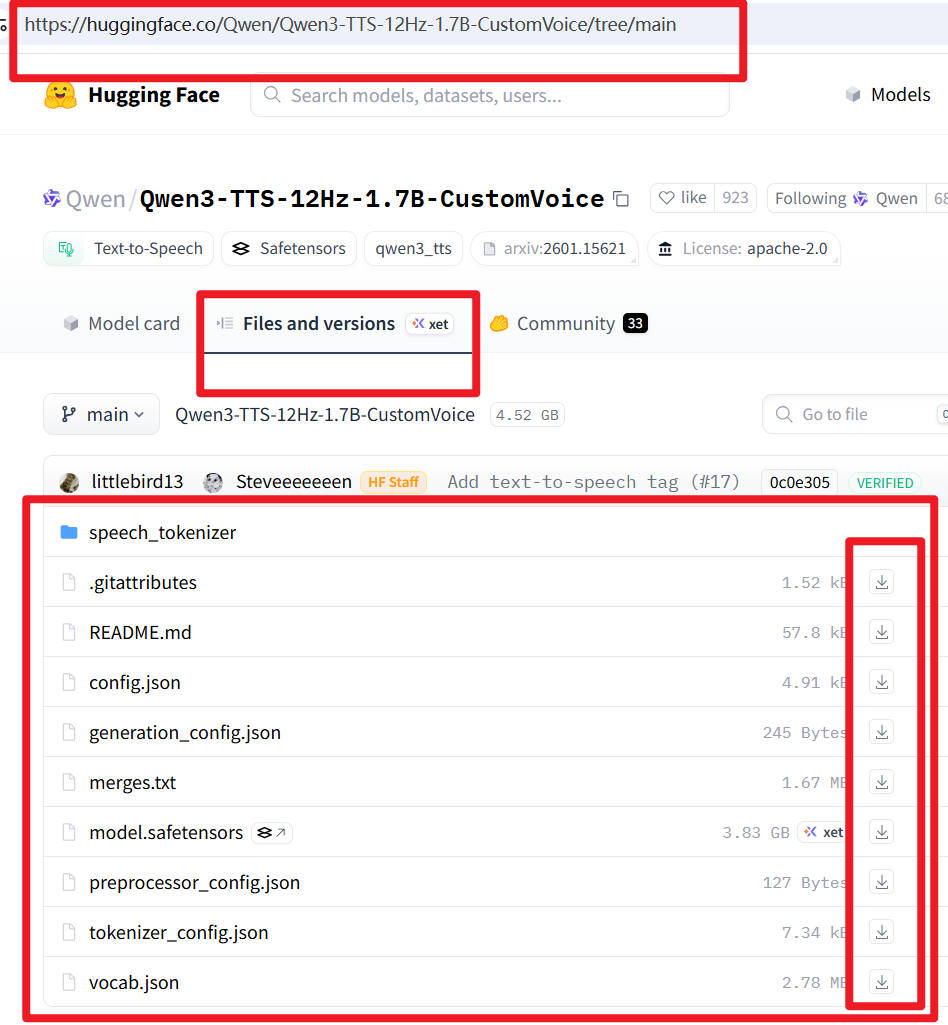
models文件夹,新建2个文件夹models--Qwen--Qwen3-TTS-12Hz-1.7B-Base和models--Qwen--Qwen3-TTS-12Hz-1.7B-CustomVoice首先打开该网址 https://huggingface.co/Qwen/Qwen3-TTS-12Hz-1.7B-Base/tree/main 将所有文件和文件夹下载后放到
models/models--Qwen--Qwen3-TTS-12Hz-1.7B-Base文件夹内再打开该网址 https://huggingface.co/Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice/tree/main 同样下载所有文件和文件夹到
models/models--Qwen--Qwen3-TTS-12Hz-1.7B-CustomVoice文件夹内如下图所示
参考音频:
适用于基于一段 3-10 秒的参考音频来克隆声音。
在 菜单--工具--TTS设置--Qwen-tts(本地),填写参考音频和该音频对应文字内容,一行一组,可在配音角色中选择使用该参考音频进行克隆
示例
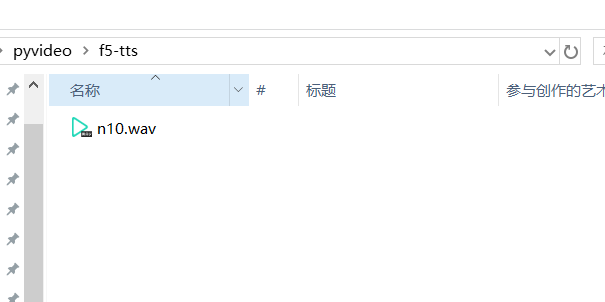
n10.wav#你说四大皆空,却为何紧闭双眼,你若挣开眼睛看看我,我不相信,你两眼空空将 n10.wav 音频文件放在软件目录下的f5-tts文件夹内,然后在#号后填写音频对应说话文本
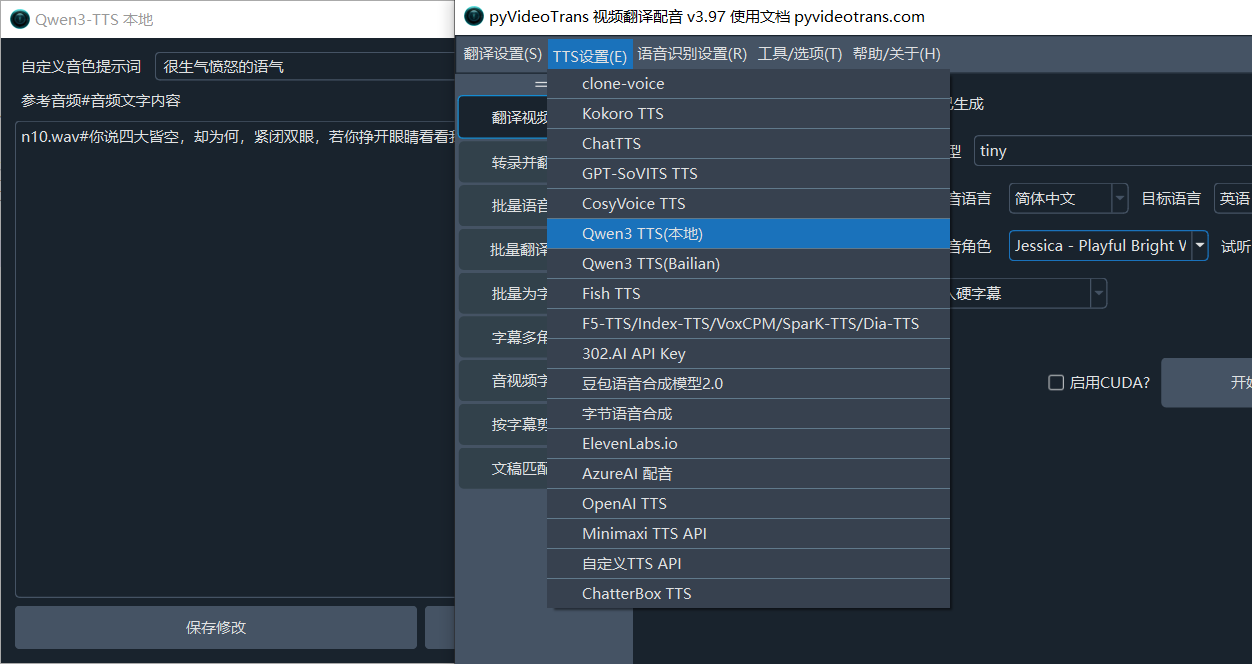
语音风格指导词
当使用Qwen-TTS模型内置的 Vivian, Uncle_fu, Sohee 预设音色时,可填写一段指导
打开 菜单--工具--TTS设置--Qwen-tts(本地) 在提示词(prompt)文本框中填写简短提示词,例如使用愤怒发疯的语气,在使用内置音色时,将自动应用该提示词。
Qwen3-TTS 阿里百炼API (在线版)
qwen3-tts模型支持10种语言和多种中文方言 模型名称
qwen3-tts-flash
{
"芊悦(Cherry)": "Cherry",
"苏瑶(Serena)": "Serena",
"晨煦(Ethan)": "Ethan",
"千雪(Chelsie)": "Chelsie",
"茉兔(Momo)": "Momo",
"十三(Vivian)": "Vivian",
"月白(Moon)": "Moon",
"四月(Maia)": "Maia",
"凯(Kai)": "Kai",
"不吃鱼(Nofish)": "Nofish",
"萌宝(Bella)": "Bella",
"詹妮弗(Jennifer)": "Jennifer",
"甜茶(Ryan)": "Ryan",
"卡捷琳娜(Katerina)": "Katerina",
"艾登(Aiden)": "Aiden",
"沧明子(Eldric Sage)": "Eldric Sage",
"乖小妹(Mia)": "Mia",
"沙小弥(Mochi)": "Mochi",
"燕铮莺(Bellona)": "Bellona",
"田叔(Vincent)": "Vincent",
"萌小姬(Bunny)": "Bunny",
"阿闻(Neil)": "Neil",
"墨讲师(Elias)": "Elias",
"徐大爷(Arthur)": "Arthur",
"邻家妹妹(Nini)": "Nini",
"诡婆婆(Ebona)": "Ebona",
"小婉(Seren)": "Seren",
"顽屁小孩(Pip)": "Pip",
"少女阿月(Stella)": "Stella",
"博德加(Bodega)": "Bodega",
"索尼莎(Sonrisa)": "Sonrisa",
"阿列克(Alek)": "Alek",
"多尔切(Dolce)": "Dolce",
"素熙(Sohee)": "Sohee",
"小野杏(Ono Anna)": "Ono Anna",
"莱恩(Lenn)": "Lenn",
"埃米尔安(Emilien)": "Emilien",
"安德雷(Andre)": "Andre",
"拉迪奥·戈尔(Radio Gol)": "Radio Gol",
"上海-阿珍(Jada)": "Jada",
"北京-晓东(Dylan)": "Dylan",
"南京-老李(Li)": "Li",
"陕西-秦川(Marcus)": "Marcus",
"闽南-阿杰(Roy)": "Roy",
"天津-李彼得(Peter)": "Peter",
"四川-晴儿(Sunny)": "Sunny",
"四川-程川(Eric)": "Eric",
"粤语-阿强(Rocky)": "Rocky",
"粤语-阿清(Kiki)": "Kiki"
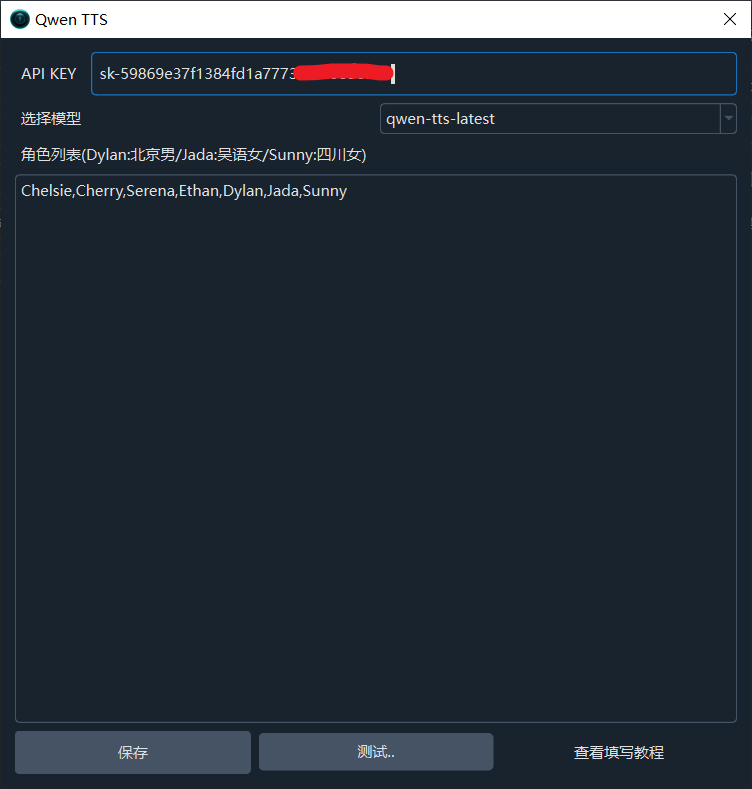
}第一步:获取并配置您的API KEY
- 请点击此链接访问阿里云百炼平台:https://bailian.console.aliyun.com/?tab=model#/api-key
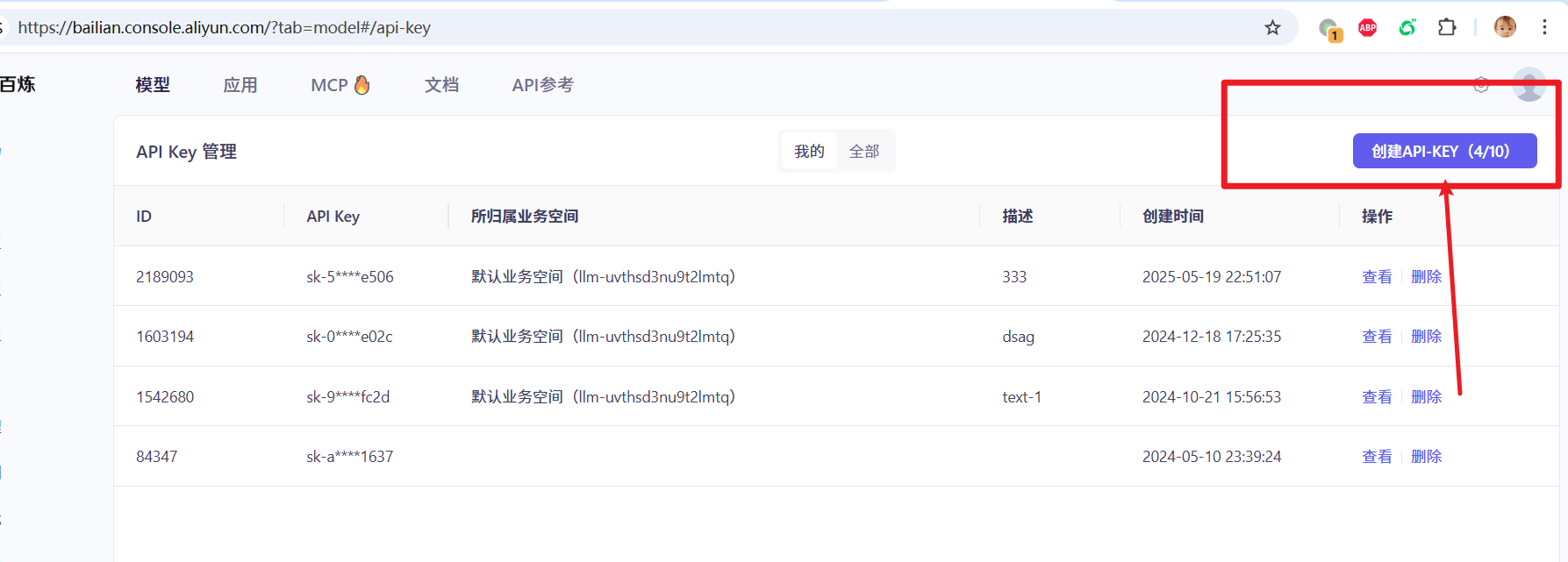
登录您的阿里云账户(若无账户,按提示注册一个即可)。
在API-KEY管理页面,点击“创建API-KEY”,系统会自动生成一串以“sk-”开头的字符,这就是您的API KEY。请复制这串字符。
回到pyVideoTrans软件,在顶部菜单栏找到 TTS设置,点击后在下拉菜单中选择 Qwen TTS。
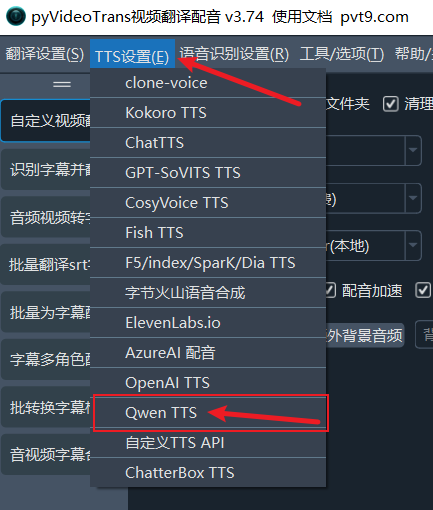
在弹出的Qwen3 TTS配置窗口中,将您刚刚复制的 API KEY 粘贴到“API KEY”输入框中。您可以点击“测试”按钮,试听一下效果,如果能听到声音,说明配置成功。最后,点击 保存。
第二步:在视频翻译中使用Qwen3-TTS
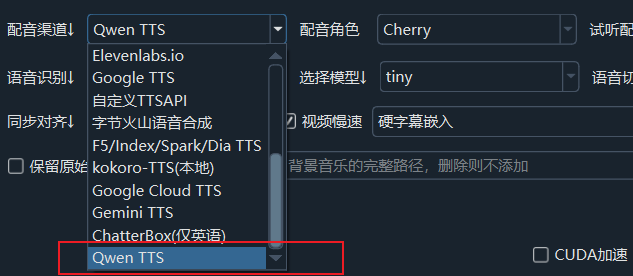
配置完成后,您就可以在处理单个视频时启用Qwen3-TTS了。
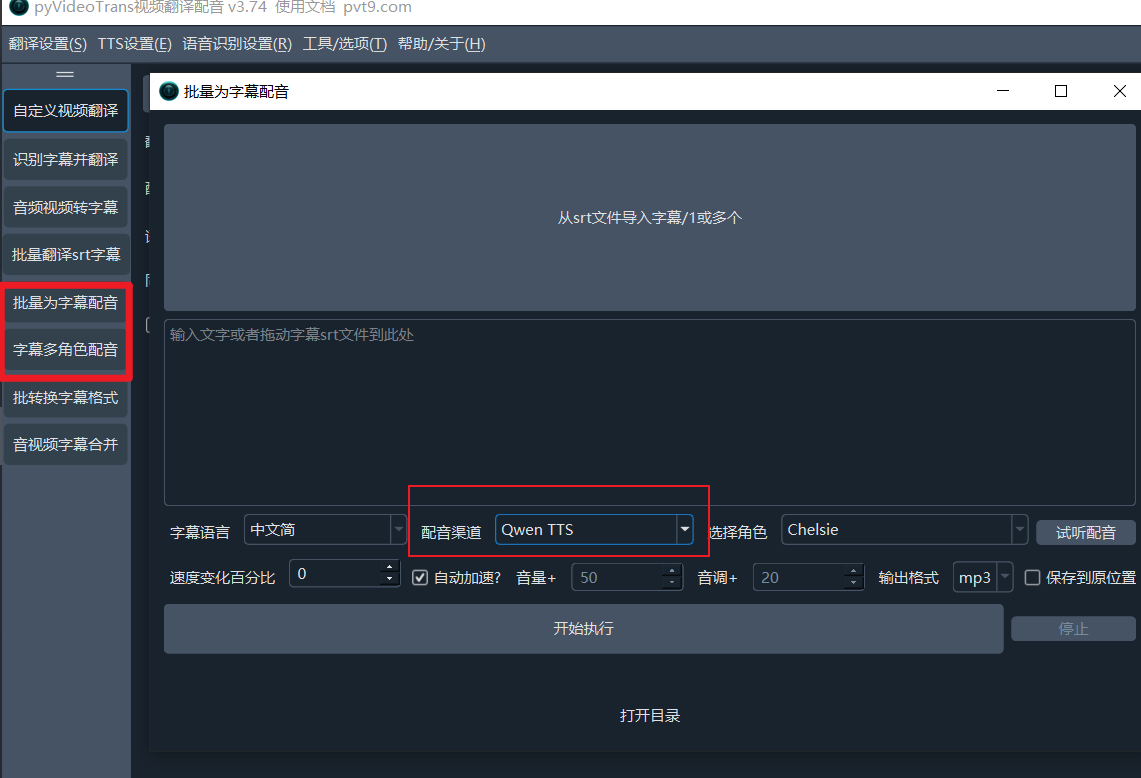
- 在pyVideoTrans的主界面,找到 “配音渠道” 的下拉菜单,点击并选择 “Qwen3 TTS”。
- 在旁边的 “配音角色” 菜单中,您可以选择您喜欢的音色,比如选择“Cherry”体验标准女声,或选择“Sunny”来一段有趣的四川话配音。
第三步:在批量配音和多角色配音中使用
Qwen-TTS的强大功能同样适用于批量处理任务,大大提升您的工作效率。
- 批量为字幕配音:如果您有多个SRT字幕文件需要配音,可以切换到 “批量为字幕配音” 界面。在下方的“配音渠道”中同样选择 “Qwen TTS” 和您想要的角色即可。
- 字幕多角色配音:在处理包含多个角色的对话时,此功能同样适用。您可以在“字幕多角色配音”功能区为不同角色分配Qwen-TTS的不同音色。