pyVideoTrans 常见问题与解决方案
为了帮助您更好地使用 pyVideoTrans,我们整理了以下常见问题及其解决方案。
在 菜单栏--帮助/关于 中有很多链接,比如模型下载地址、CUDA配置等,遇到问题时可尝试点开使用。
如何查看日志:软件根目录下的
logs/文件夹有按日期命名的.log日志文件。报错时可复制日志底部约 30 行内容寻求帮助。如何恢复出厂设置:删除
videotrans/目录下的cfg.json、params.json、codec.json、ass.json四个文件,重启软件即可。
第一部分:安装与启动问题
1. 双击 sp.exe 后,软件无法打开或长时间没有反应?
这通常是正常现象,请不要着急。
- 原因:本软件基于
PySide6开发,主界面包含较多组件,首次加载时需要初始化,这会消耗一些时间。根据您的电脑性能,启动时间可能在 5秒到2分钟 不等。 - 解决方案:
- 耐心等待:双击后请耐心等待一段时间。
- 检查安全软件:部分杀毒软件或安全卫士可能会阻止程序启动,请尝试暂时关闭它们,或将本软件添加到信任/白名单中。
- 检查文件路径:确保软件存放的路径只包含英文和数字,不应有中文、空格或特殊符号。例如,
D:\pyVideoTrans是一个好的路径,而D:\program file\视频 工具则可能导致问题。 - 升级包问题:如果您是覆盖了升级包后无法启动,说明操作有误。请重新下载完整的软件包,解压后再覆盖新版升级包。
2. 启动时提示缺少 python310.dll 文件怎么办?
这个问题说明您只下载了升级补丁包,而没有下载主程序。
- 解决方案:
- 请先前往官网下载 完整软件包。
- 解压完整包到指定目录。
- 之后再下载最新的升级补丁包,覆盖到完整包的目录中即可。
3. 软件需要安装吗?
本软件是绿色版,无需安装。下载完整包后解压,双击 sp.exe 即可直接运行。
4. 为什么杀毒软件会报病毒或拦截?
- 原因:本软件使用
PyInstaller工具打包,并且没有进行商业数字签名认证。一些安全软件会基于此启动风险预警,这属于常见误报。 - 解决方案:
- 添加信任:将本软件添加到您杀毒软件的信任区或白名单中。
- 源码运行:如果您是开发者,也可以选择从源代码直接部署运行,以完全避免此问题。
5. 软件支持 Windows 7 系统吗?
不支持。软件依赖的许多核心组件(如 PyTorch、PySide6)已不再支持 Windows 7 系统。请使用 Windows 10 或 Windows 11。
6. macOS / Linux 如何部署源码?
- 前置依赖:
- Python 3.10
- FFmpeg(
brew install ffmpeg/apt install ffmpeg) - uv 包管理器
- libsndfile
- 部署步骤:bash
git clone https://github.com/jianchang512/pyvideotrans cd pyvideotrans uv sync uv run sp.py - 可选依赖:
uv sync --all-extra安装所有可选渠道(qwen-tts, qwen-asr, moss-tts, chatterbox)
7. 源码部署后启动报错怎么办?
常见原因及解决方案:
- FFmpeg 未安装:确保系统已安装 FFmpeg 且配置了环境变量
- 依赖缺失:运行
uv sync重新安装依赖 - Python 版本不对:必须使用 Python 3.10(
.python-version文件已指定)
第二部分:核心功能与设置
8. 如何提升语音识别的准确率?
识别准确率主要取决于您选择的模型大小和设置。
- 模型选择:在 "faster" 或 "openai" 模式下,模型越大,准确率越高,但处理速度越慢、资源消耗也越大。
tiny: 体积最小,速度最快,但准确率较低。base/small/medium: 效果与资源消耗居中,是常用的选项。large-v3: 体积最大,效果最好,对硬件要求也最高(需要 8GB+ 显存)。
- 优化设置:点击
菜单--工具--高级选项
找到 faster/openai语音识别调整 部分,进行如下修改:
- 语音阈值 设为
0.5 - 最短持续时间/毫秒 设为
3000 - 最大语音持续时间/秒 设为
6 - 静音分隔毫秒 设为
140 - 热词:如果视频中有专有名词,可以在此填写,以逗号分隔
- 降噪处理:如果视频有背景音乐或噪声,点击
设置更多参数选中分离人声背景声,可以显著提升识别效果。
9. 为什么处理后的视频清晰度/质量降低了?
任何涉及重新编码的操作都会不可避免地导致视频质量损失。如果您希望最大程度地保持原始画质,请确保满足以下所有条件:
- 原始视频格式:使用兼容性最好的 H.264 (libx264) 编码的 MP4 文件。
- 禁用慢速处理:在功能选项中,不要勾选"视频自动慢速"。
- 不嵌入硬字幕:可以选择不嵌入字幕,或只嵌入软字幕。硬字幕会强制重新编码整个视频。
- 高级选项-视频输出质量控制:数字默认23,可以降低到18或更低(最低0),越低输出视频质量越高,但尺寸也越大
- 高级选项-输出视频压缩率:默认是
fast,可用选择slow或slower,质量会更高,但输出耗时将增加 - 高级选项-264/265编码:默认是
264,可选265,输出视频质量更高
10. 为什么输出视频超级大?
- 修改高级选项-视频输出质量控制 为 25-51 越大输出视频尺寸越小,但质量也随之降低
- 高级选项-264/265编码:选择265,同质量下 265 尺寸更小
11. 如何配置网络代理?
部分翻译或配音服务(如 Google、OpenAI、Gemini)在国内无法直接访问,需要通过网络代理。
- 设置方法:在主界面的"网络代理地址"文本框中,填入您的代理服务地址。
- 格式要求:通常是
http://127.0.0.1:10808这样的格式(端口号需根据您的代理客户端设置填写)。 - 重要提示:如果您不了解代理或没有可用的代理服务,请将此项留空。错误的设置将导致报错。
- 国内 API 不需要代理:百度翻译、腾讯翻译、阿里翻译、DeepSeek、智谱AI、字节火山等国内 API 默认不走代理。
- 本地服务不需要代理:GPT-SoVITS、ChatTTS、F5-TTS 等本地服务自动绕过代理。
12. 如何自定义字幕的字体、颜色和样式?
点击主界面中 -> 设置更多参数 -> 修改硬字幕
第三部分:语音识别问题
13. 识别结果为空或乱码
- 原因:可能语言选择错误、视频无有效人声、或显存不足
- 解决方案:
- 检查"原始语言"是否选择正确(不要过度依赖 Auto)
- 检查视频是否有背景音乐干扰(尝试开启降噪)
- 显存不足:降低
beam_size,改用int8量化,或使用small模型 - 尝试更换识别渠道(如从 faster-whisper 换成 openai-whisper)
14. 识别速度非常慢
- 原因:使用了大型模型但未启用 GPU 加速
- 解决方案:
- 启用 CUDA 加速:确保已安装 CUDA 12.8+ 和 cuDNN 9.x,勾选
CUDA加速 - 使用小模型:将
large-v3换成medium或small - CPU 模式优化:在高级选项中将
计算数据类型改为int8
- 启用 CUDA 加速:确保已安装 CUDA 12.8+ 和 cuDNN 9.x,勾选
15. 提示显存或内存不足(Unable to allocate、CUDA out of memory)
- 原因:模型太大或显存被其他程序占用
- 解决方案(按推荐顺序尝试):
- 使用更小的模型:将识别模型从
large-v3更换为medium、small或base。large-v3模型最低需要 8GB 显存。 - 调整高级设置:在菜单栏
工具/选项->高级选项中进行如下修改:CUDA数据类型: 将float32改为float16或int8beam_size: 将5改为1best_of: 将5改为1上下文: 将true改为false
- 检查多显卡:如果有多个可用显卡,检查第一块显卡可用显存是否过小。软件默认使用第一块显卡,升级到 v3.98-317 以上版本会自动选择显存最大的显卡。
- 使用更小的模型:将识别模型从
16. 说话人识别不准确
- 原因:说话人分离模型对某些场景(如多人同时说话、背景噪声大)效果有限
- 解决方案:
- 在
设置更多参数中勾选识别说话人并指定人数 - 在高级选项中切换说话人模型(内置、阿里CAM++、pyannote)
- 使用 pyannote 模型需要在 HuggingFace 上申请 token 并同意授权协议
- 在
17. LLM 重新断句后结果更差
- 原因:本地小模型(如 7B)智能不足,或提示词过于复杂
- 解决方案:
- 使用更强的在线模型(DeepSeek-V3、GPT-4o 等)
- 精简提示词(在
videotrans/prompts/recharge/recharge-llm.txt中修改) - 使用
clone角色克隆原音色时,不建议使用 LLM 重新断句
18. 配音后字幕和声音不同步
这是翻译配音中的常见现象,源于语言间的时长差异。
- 原因:不同语言表达同一意思时,音节数和语法结构不同,导致配音时长与原始字幕时长不一致。例如,一句2秒的中文,翻译成英文后配音时长可能变为3-4秒。
- 解决方案:
- 启用音频加速:勾选
音频加速,自动将过长的配音加速到匹配字幕时长 - 启用视频慢速:勾选
视频慢速,放慢视频画面以匹配配音时长 - 两者同时启用:当倍率 > 1.2x 时,音频加速和视频慢速各负担一半时间差
- 调整语速:设置
配音语速值(如+10%)加快整体配音速度 - 使用二次识别:勾选
二次识别,在配音完成后再次识别生成更精准的字幕时间轴
- 启用音频加速:勾选
详细原理请参考 音频视频时间轴对齐原理说明
19. 二次识别是什么?什么时候需要?
二次识别是在配音完成后,对生成的配音音频再次进行语音识别,生成时间轴更精准、字数更简短的字幕。
- 适用场景:选择了
嵌入单字幕(硬字幕或软字幕),且需要字幕和配音精确对齐 - 设置方法:勾选
二次识别,在高级选项中设置二次识别的最长/最短语音持续时间 - 注意:二次识别需要额外的处理时间
第四部分:翻译问题
20. 翻译结果有空白行或包含提示词
- 原因:本地小模型智能不足,或 AI 合并了字幕行
- 解决方案:
- 本地小模型(如 7B)智能不足,建议改用 DeepSeek/GPT-4 等在线模型
- 取消"发送完整字幕"选项,改为按行翻译
- 设置
trans_thread=1降低并发 - 具体原理和解决方法点击查看
21. AI 翻译触发安全限制被过滤
- 错误信息:
内容触发AI风控被过滤 - 原因:翻译内容被 AI 服务的安全系统拦截
- 解决方案:
- 手动编辑字幕,移除可能触发风控的内容
- 更换翻译渠道(如从 OpenAI 换成 DeepSeek)
22. 翻译结果与原文不对应(字幕行错位)
- 原因:AI 翻译时合并了字幕行,导致行号错位
- 解决方案:
- 在高级选项中取消勾选"发送完整字幕"
- 将翻译并发数设为 1
- 使用支持大上下文的在线 AI 模型
23. 翻译缓存导致结果异常
- 原因:翻译结果被缓存,修改提示词或翻译渠道后未生效
- 解决方案:
- 勾选主界面的
清理已生成选项 - 或手动删除
tmp/translate_cache/目录下的缓存文件
- 勾选主界面的
第五部分:配音问题
24. Edge-TTS 报错 403 或生成静音
- 原因:微软限流,短时间内请求过多
- 解决方案:
- 在"高级选项"中将"同时配音线程数"设为 1
- 将"配音后暂停秒数"设为 5-10 秒
- 如果使用了代理,Edge-TTS 可能因代理问题失败。在软件根目录创建
edgetts-noproxy.txt空文件可强制绕过代理
25. F5-TTS / CosyVoice / GPT-SoVITS 无法连接
- 原因:本地 TTS 服务未启动或地址配置错误
- 解决方案:
- 确保外部 TTS 服务的终端窗口未关闭
- 检查 API 地址是否正确(注意端口号)
- GPT-SoVITS 需启动
api.py或api_v2.py,不能使用网页版 7860 端口 - 如果填写了
0.0.0.0作为地址,改为127.0.0.1
26. GPT-SoVITS 报错 {"detail":"Not Found"}
- 原因:API 版本不匹配或端口错误
- 解决方案:
- 检查启动的是
api.py还是api_v2.py,在软件中勾选对应的api_v2?选项 - 确保填写的是 API 地址(默认 9880),而非网页版地址(7860)
- 检查启动的是
27. Index-TTS 报错 Value: 'Same as the voice reference' is not in the list
- 原因:Index-TTS 内部多语言翻译不一致的 Bug
- 解决方案:打开 Index-TTS 项目根目录的
webui.py,将i18n("与音色参考音频相同")替换为Same as the voice reference
28. Azure-TTS 报错 Could not find module Microsoft.CognitiveServices.Speech.core.dll
- 原因:缺少微软 VC++ 运行库
- 解决方案:
- 如果是下载的补丁包,请重新下载完整包
- 如果已是完整包,安装 微软 VC++ 运行时集合包 后重启电脑
29. 配音后声音有机械感或杂音
- 原因:音频加速倍率过高(> 3x),或参考音频质量差
- 解决方案:
- 启用视频慢速,与音频加速协同分担时间差
- 提升参考音频质量:使用清晰的 5-10 秒单人声 WAV 文件
- 勾选
分离人声背景声,去除背景噪声
第六部分:声音克隆问题
30. 使用 clone 角色配音失败或音质差
- 原因:参考音频时长不在 3-10 秒范围内,或字幕时间轴被 LLM 重新断句打乱
- 解决方案:
- 禁止使用 LLM 重新断句:LLM 重新断句会打乱时间轴,导致参考音频截取错位
- 强制控制字幕时长:在
高级选项 -> 语音识别参数中,将最长语音持续秒数设为 6-10,最短语音持续毫秒设为 3000-4000 - 勾选
合并过短字幕到邻近和Whisper预分割音频 - 使用
OmniVoice-TTS渠道,对短参考音频兼容性更好 - 勾选
分离人声背景声,提升参考音频质量
31. 如何使用自定义参考音频?
- 录制或截取一段 5-10 秒的 WAV 格式音频(单人声、无背景噪声)
- 将音频复制到软件目录下的
f5-tts文件夹 - 打开
菜单 -> TTS 设置 -> 设置参考音频,填写文件名.wav#音频中的说话文本 - 在主界面配音角色下拉框中选择该文件名
注意:GPT-SoVITS 的参考音频需要放在 GPT-SoVITS 软件的根目录下,而非
f5-tts文件夹。
第七部分:视频合成与输出问题
32. 执行过程中报错 ffprobe exec error 或 ffmpeg 相关异常
- 原因:文件路径过长或含有特殊符号
- 解决方案:
- 将视频文件移动到更浅的目录(如
D:\videos) - 重命名为简短的英文或数字名称
- 删除文件名中的特殊符号(
?*、表情符号等)
- 将视频文件移动到更浅的目录(如
33. 软件提示视频"不含音轨"
- 可能原因 1:视频确实没有声音(从某些网站下载时画面和声音分离)
- 可能原因 2:视频编码格式不支持(如 AV1)
- 可能原因 3:背景噪音过大,人声被掩盖
- 解决方案:
- 用播放器本地播放确认是否有声音
- 尝试先将视频转换为标准 H.264/MP4 格式
- 开启降噪或人声分离功能
34. 如何输出无损视频?
当满足以下所有条件时,视频将无损输出(不重新编码):
- 原始视频编码为
mp4/h.264/yuv420p - 高级选项中
264/265编码选择264 - 未启用
视频慢速 - 未嵌入
硬字幕(软字幕不影响)
注意:若配音后时长大于视频原时长,超出部分会被截断。
35. 处理后出现声音、字幕、画面不同步
这是语言翻译中的正常现象。
- 原因:不同语言表达同一个意思时,句子的长度和音节数均不同,发音时长必然发生变化。
- 解决方案:
- 启用
音频加速和/或视频慢速 - 设置
配音语速(如+10%)加快整体速度 - 启用
二次识别生成更精准的字幕时间轴 - 详细原理请参考 音频视频时间轴对齐原理说明
- 启用
36. 总是提示显存不足 (例如 Unable to allocate 错误)
这个错误意味着您的显卡没有足够的显存或内存来执行当前任务。
- 解决方案(按推荐顺序尝试):
- 使用更小的模型:将识别模型从
large-v3更换为medium、small或base - 调整高级设置:
CUDA数据类型: 将float32改为float16或int8beam_size: 将5改为1best_of: 将5改为1上下文: 将true改为false
- 使用更小的模型:将识别模型从
37. 已经安装了 CUDA,为什么软件还是无法使用 GPU 加速?
请检查以下可能的原因:
- CUDA 版本不兼容:本软件要求 CUDA 12.8 及以上版本
- 显卡驱动过旧:请更新您的 NVIDIA 显卡驱动到最新版本
- 缺少 cuDNN:确保已安装 cuDNN 9.x 并配置了环境变量
- 硬件不兼容:GPU 加速仅支持 NVIDIA 显卡(N卡)。AMD 或 Intel 显卡无法使用 CUDA
- 环境变量未配置:检查系统环境变量中是否包含 CUDA 的
bin和lib目录
38. GPU 使用率很低,正常吗?
正常。软件的工作流程是:语音识别 -> 文字翻译 -> 文本配音 -> 视频合成。
只有在第一步 "语音识别" 阶段,才会大量使用 GPU 进行运算。其他阶段(如翻译、合成)主要依赖 CPU,因此 GPU 在大部分时间处于低负载状态是符合预期的。
39. 处理几个视频后,发现硬盘空间被占满?
这通常是由于启用了"视频慢速"功能并产生了大量临时文件。
- 原因:该功能会将视频按字幕切割成许多小片段,并对每个片段进行处理,这会产生远超原视频体积的缓存文件。
- 解决方案:
- 手动清理:处理完成后,手动删除软件根目录下的
tmp/文件夹内的所有内容 - 自动清理:正常关闭软件时,程序会自动清理这些缓存
- 手动清理:处理完成后,手动删除软件根目录下的
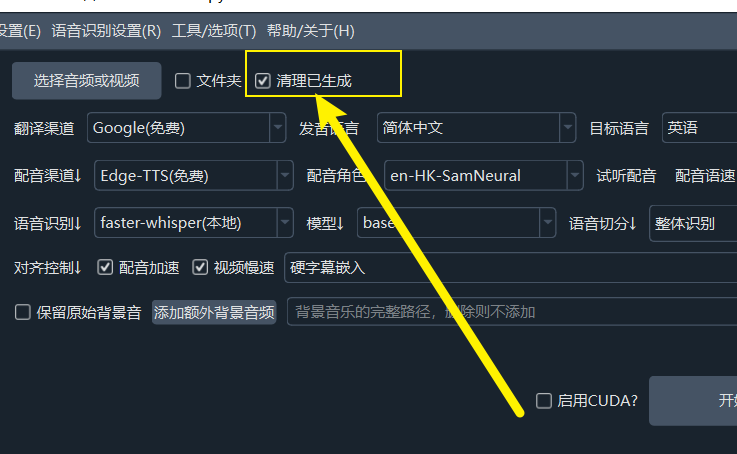
40. 反复处理同一个视频,为什么识别结果和字幕总是不变?
- 原因:软件默认启用了缓存机制,如果检测到某个视频已经生成过字幕文件,会直接使用缓存结果
- 解决方案:在软件主界面的左上角,勾选
清理已生成复选框
第八部分:批量处理问题
41. 批量翻译视频时总是会卡住
默认批量任务时,会将每个任务分为多个阶段,同时交叉并行处理,太多任务时可能导致资源耗尽。
- 解决方案:选中 高级选项--批量翻译时强制串行,将执行方式改为串行处理
42. 批量处理时如何控制并发数量
在 高级选项 -> 通用设置 中:
CPU同时任务数:最大 CPU 同时任务数,不超过 CPU 核数GPU同时任务数:GPU 任务同时执行数量,除非多卡或单卡显存 > 24G,否则设为 1批量翻译视频时每批数量:设为 1 可逐个处理,设为 0 则全部同时处理
第九部分:高级选项详解
43. 音频加速和视频慢速的区别?
| 选项 | 效果 | 适用场景 |
|---|---|---|
| 音频加速 | 加速配音以匹配字幕时长,音质可能略有损失 | 配音比字幕长 1-2 倍 |
| 视频慢速 | 慢放视频以匹配配音时长,画面可能略卡 | 配音比字幕长 2 倍以上 |
| 两者同时 | 各负担一半时间差,效果最佳 | 配音远长于字幕 |
44. 发送完整字幕 有什么作用?
选中后,AI 翻译时会附带行号和时间轴发给 AI,翻译质量更好但可能合并行。建议:
- 使用在线大模型(DeepSeek、GPT-4o)时选中
- 使用本地小模型时取消选中
45. 二次识别 与 LLM重新断句 的区别?
| 选项 | 时机 | 作用 |
|---|---|---|
| LLM重新断句 | 语音识别后 | AI 修正错别字、重新切分长文本 |
| 二次识别 | 配音完成后 | 对配音音频再次识别,生成更精准的时间轴 |
使用
clone角色时,不建议使用 LLM 重新断句。
46. 嵌入字幕类型如何选择?
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 不嵌入字幕 | 只替换声音,不添加字幕 | 仅需配音 |
| 嵌入硬字幕 | 字幕永久烧录到画面,无法关闭 | 任何播放器都能显示 |
| 嵌入软字幕 | 字幕作为独立轨道,播放器可开关 | 需要灵活控制字幕显示 |
| 嵌入硬字幕(双) | 中英双语硬字幕 | 需要双语对照 |
| 嵌入软字幕(双) | 中英双语软字幕 | 需要双语对照且可关闭 |
第十部分:文件与路径问题
47. 输入文件路径有什么要求?
- 路径长度:Windows 命令行有 260 字符限制,文件路径应尽量简短
- 特殊符号:文件名中不应包含
?*、表情符号等特殊符号 - 中文路径:虽然支持,但建议使用英文路径以避免兼容性问题
- 空格:路径中可以有空格,但建议避免
48. 输出文件保存在哪里?
- 默认位置:原视频目录下的
_video_out/文件夹 - 独立功能输出:批量转录、配音、翻译 SRT 等功能输出到
output/目录 - 自定义输出:可在主界面设置输出目录
49. 如何导入已有的 SRT 字幕?
- 在视频文件同级目录下创建
_video_out/文件夹 - 在其中创建视频同名子文件夹(如
myvideo-mp4,必须带格式后缀) - 将字幕文件复制到子文件夹,重命名为
zh-cn.srt(源语言)和en.srt(目标语言) - 导入视频执行翻译,软件会自动跳过 ASR 和翻译阶段
第十一部分:CLI 命令行问题
50. CLI 基本用法
uv run cli.py --task <任务类型> --name "<文件路径>" [其他参数]任务类型:stt(语音转录)、tts(文字配音)、sts(字幕翻译)、vtv(视频翻译)
51. 如何查看可用的渠道和语言?
uv run cli.py --list providers # 查看所有渠道
uv run cli.py --list languages # 查看所有语言代码
uv run cli.py --list models # 查看 faster-whisper 模型52. CLI 常见报错
--name is required:未指定输入文件File not found:文件路径错误或文件不存在--voice_role is required:TTS 模式下必须指定配音角色--target_language_code is required:STS/VTV 模式下必须指定目标语言
第十二部分:综合信息
53. 软件是否支持 Docker 部署?
支持。使用webui界面
54. 能否识别视频画面中的硬字幕(OCR 功能)?
不能。本软件的原理是分析视频中的音频轨道,识别出人类的语音并转换为文字。它不具备图像文字识别(OCR)功能。 若有需要,可以点击查看另一个项目,提取视频中硬字幕
55. 我可以添加新的语言支持吗?
56. 软件是否收费?可以商用吗?
- 费用:本项目是一个免费且开源的软件,您可以免费使用所有功能。请注意,如果您使用第三方的翻译或TTS或语音转录接口,这些服务商可能会收取费用,但这与本软件无关。
- 商用:个人和公司均可自由使用本软件。但如果您希望将本项目的代码集成到您自己的商业产品中,则必须遵守 GPL-v3 开源协议。此外某些渠道使用的模型或在线API可能有他们自己的协议要求,是否允许商用,请咨询所使用的渠道对应的平台。
57. 是否提供人工客服?
没有。本项目为个人开发的免费开源软件,没有盈利,因此无法配备专门的人工客服团队。如果您遇到问题,请先仔细阅读本 FAQ。 或你也可以选择软件右下角微信二维码打赏,留言你的微信号,获取有偿技术支持。
58. 从哪里下载软件和模型?
59. 报错与日志
- 日志位置:软件根目录下的
logs文件夹有当前年月日命名的 log 格式日志文件 - 反馈方式:报错时点击弹窗的"报告错误"可自动提交至官方论坛;或复制日志底部 30 行内容询问 AI
60. 新版本为什么在发音语言列表中没有了"自动检测"?
在 "批量语音转字幕" 功能面板中可以选择"自动检测",在"翻译视频或音频"功能中去掉了自动检测。因为视频翻译后续工作如字幕翻译、配音(涉及参考音频)等某些渠道需要明确指定原始语言,否则会报错。如果你仅仅想转录语音为字幕,可单独使用左侧面板中的"批量语音转字幕"功能。
快速问题排查表
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 软件无法启动 | 杀毒软件拦截 / 路径问题 | 添加信任白名单 / 移至英文路径 |
| 缺少 python310.dll | 只下载了补丁包 | 下载完整包再覆盖补丁 |
| 识别结果为空 | 语言选择错误 / 无有效人声 | 正确选择语言 / 开启降噪 |
| 显存不足 | 模型太大 | 换小模型 / 改 int8 / 降 beam_size |
| GPU 未启用 | CUDA 未安装 / 驱动过旧 | 安装 CUDA 12.8+ / 更新驱动 |
| 翻译有空白行 | AI 合并了字幕行 | 取消"发送完整字幕" / 用在线模型 |
| Edge-TTS 403 | 微软限流 | 降并发 / 加暂停秒数 |
| 声音字幕不同步 | 语言时长差异 | 启用音频加速 / 视频慢速 |
| ffprobe 报错 | 路径过长或特殊符号 | 简化文件名 / 移至浅层目录 |
| 硬盘空间占满 | 视频慢速产生大量临时文件 | 清理 tmp/ 文件夹 |
| clone 配音差 | 参考音频时长不当 | 控制 3-10 秒 / 禁用 LLM 断句 |
| GPT-SoVITS 404 | API 版本不匹配 | 检查 api.py vs api_v2.py |